
I host a few small low-traffic websites for local interests. I do this for free - and some of them are for a friend who died last year but didn’t want all his work to vanish. They don’t get so many views, so I was surprised when I happened to glance at munin and saw my bandwidth usage had gone up a lot.
I spent a couple of hours working to solve this and did everything wrong. But it was a useful learning experience and I thought it might be worth sharing in case anyone else encounters similar.
My setup is:
Cloudflare DNS -> Cloudflare Tunnel (Because my residential isp uses CGNAT) -> Haproxy (I like Haproxy and amongst other things, alerts me when a site is down) -> Separate Docker containers for each website. On a Debian server living in my garage.
From Haproxy’s stats page, I was able to see which website was gathering attention. It’s one running PhpBB for a little forum. Tailing apache’s logs in that container quickly identified the pattern and made it easy to see what was happening.
It was seeing a lot of 404 errors for URLs all coming from the same user-agent “claudebot”. I know what you’re thinking - it’s an exploit scanning bot, but a closer look showed it was trying to fetch normal forum posts, some which had been deleted months previously, and also robots.txt. That site doesn’t have a robots.txt so that was failing. What was weird is that the it was requesting at a rate of up to 20 urls a second, from multiple AWS IPs - and every other request was for robots.txt. You’d think it would take the hint after a million times of asking.
Googling that UA turns up that other PhpBB users have encountered this quite recently - it seems to be fascinated by web forums and absolutely hammers them with the same behaviour I found.
So - clearly a broken and stupid bot, right? Rather than being specifically malicious. I think so, but I host these sites on a rural consumer line and it was affecting both system load and bandwidth.
What I did wrong:
-
In docker, I tried quite a few things to block the user agent, the country (US based AWS, and this is a UK regional site), various IPs. It took me far too long to realise why my changes to .htaccess were failing - the phpbb docker image I use mounts the root directory to the website internally, ignoring my mounted vol. (My own fault, it was too long since I set it up to remember only certain sub-dirs were mounted in)
-
Figuring that out, I shelled into the container and edited that .htaccess, but wouldn’t have survived restarting/rebuilding the container so wasn’t a real solution.
Whilst I was in there, I created a robots.txt file. Not surprisingly, claudebot doesn’t actually honour whats in there, and still continues to request it ten times a second.
- Thinking there must be another way, I switched to Haproxy. This was much easier - the documentation is very good. And it actually worked - blocking by Useragent (and yep, I’m lucky this wasn’t changing) worked perfectly.
I then had to leave for a while and the graphs show it’s working. (Yellow above the line is requests coming into haproxy, below the line are responses).
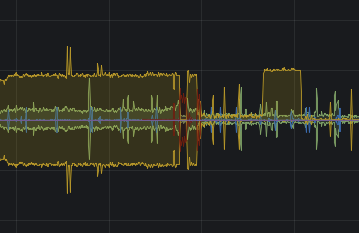
Great - except I’m still seeing half of the traffic, and that’s affecting my latency. (Some of you might doubt this, and I can tell you that you’re spoiled by an excess of bandwidth…)
- That’s when the penny dropped and the obvious occured. I use cloudflare, so use their firewall, right? No excuses - I should have gone there first. In fact, I did, but I got distracted by the many options and focused on their bot fighting tools, which didn’t work for me. (This bot is somehow getting through the captcha challenge even when bot fight mode is enabled)
But, their firewall has an option for user agent. The actual fix was simply to add this in WAF for that domain.
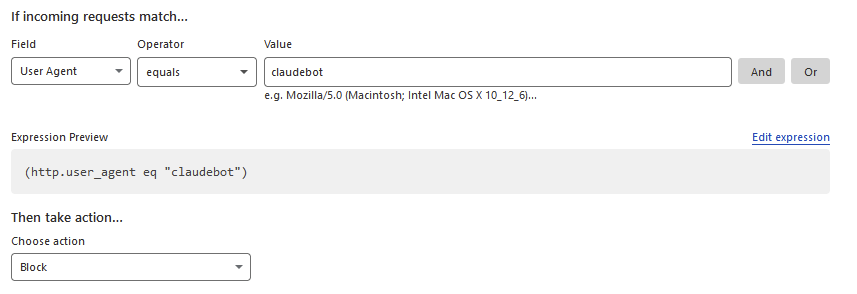
And voila - no more traffic through the tunnel for this very rude and stupid bot.
After 24 hours, Cloudflare has blocked almost a quarter of a million requests by claudebot to my little phpbb forum which barely gets a single post every three months.

Moral for myself: Stand back and think for a minute before rushing in and trying to fix something in the wrong way. I’ve also taken this as an opportunity to improve haproxy’s rate limiting internally. Like most website hosts, most of my traffic is outbound, and slowing things down when it gets busy really does help.
This obviously isn’t a perfect solution - all claudebot has to do is change its UA, and by coming from AWS it’s pretty hard to block otherwise. One hopes it isn’t truly malicious. It would be quite a lot more work to integrate Fail2ban for more bots, but it might yet come to that.
Also, if you write any kind of web bot, please consider that not everyone who hosts a website has a lot of bandwidth, and at least have enough pride to write software good enough to not keep doing the same thing every second. And, y’know, keep an eye on what your stuff is doing out on the internet - not least for your own benefit. Hopefully AWS really shaft claudebot’s owners with some big bandwidth charges…
EDIT: It came back the next day with a new UA, and an email address linking it to anthropic.com - the Claude3 AI bot, so it looks like a particularly badly written scraper for AI learning.
Pretty sure expiry is handled by the local crowdsec daemon, so it should automatically revoke rules once a set time is reached.
At least that’s the case with the iptables and nginx bouncers (4 hour ban for probing). I would assume that it’s the same for the cloudflare one.
Alternatively, maybe look into running two bouncers (1 local, 1 CF)? The CF one filters out most bot traffic, and if some still get through then you block them locally?
I’ve just installed crowdsec and its haproxy plugin. Documentation is pretty good. I need to look into getting it to ban the ip at cloudflare - that would be neat.
Annoyingly, the claudebot spammer is back again today with a new UA. I’ve emailed the address within it politely asking them to desist - be interesting to see if there’s a reply. And yes, it is Claudebot 3 - AI.
iirc the bad UA filter is bundled with either base-http-scenarios or nginx. That might help assuming they aren’t trying to mask that UA.