

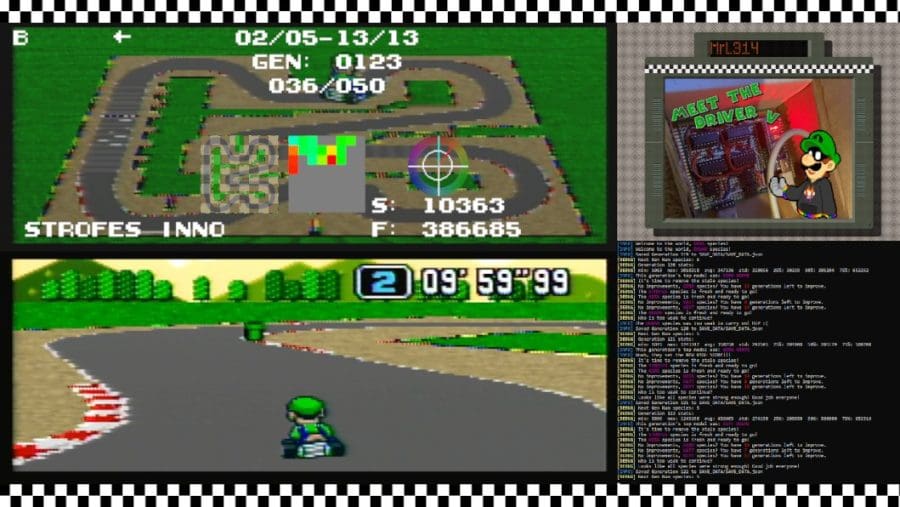
A recent project has seen a computer learning to play the classic game Super Mario Kart on a real Super Nintendo Entertainment System (SNES) using an evolutionary algorithm. The program, named LuEAgi, was developed by LF_MrL314. The AI is designed to learn how to play with minimal information provided.
LuEAgi mimics the concept of natural selection in its learning process, repeatedly attempting tasks and learning from mistakes to improve its strategies for gaming challenges effectively.
The question is, of course, does Skynet start out by beating us at Mario Kart?
Twitch Plays Pokemon was better.
ALL HAIL LORD HELIX
Shortly after, “AI learns to speak after learning to play Mario Kart, immediately complains about the bullshit rubberbanding.”
I remember during the pandemic lockdown, I would watch on youtube a live stream of a programing trying to learn to play the NES game Super Mario Bros. It took 4 days for it to learn to go right.
It was the kind of stream that you would watch for 2-3 minutes at a time. It live streamed 24/7 for months. You’d pop in once or twice a day, learn what the computer learned, and after a few minutes you saw it making the same mistakes time after time after time.
But the next day, you’d come in and find that he made it past the pitt he was falling down yesterday.
I was there, after 9 days nonstop playing, he finally beat 1-1 for the first time! Everybody celebrated so hard for about 5 seconds. Then on 1-2 he immediately ran left, and died to the first goomba without any attempt to dodge.
I can only imagine this AI will be just as boring to watch for long periods, but exciting to watch over the coarse of weeks/months.
I can’t help but think that if the “AI” performed that poorly on a new level, it wasn’t just learning the wrong things but the entire approach wasn’t right.
The “learning” isn’t the same kind of learning that humans do. There is no abstraction or meta layer, only whether or not a sequence of inputs achieved an output deemed successful by a human. Programs like these interact with the game, essentially, as one static screen shot at a time. For any given configuration, the input that is most likely to result in success (based on prior experience in the form of training) is reinforced so it becomes more likely, a bit like training a dog. Except a dog knows what a ball is.
This is similar to how Google’s Go models worked. For any given configuration, a set of probabilities are generated based on the weights in the model, which are based on the training (initial values are arbitrary). The main difference is that Google could simulate zillions of AI vs. AI games at a high rate of speed. Anything with a live stream attached is mainly for entertainment value and subscriber count, otherwise you would have the game run at 1,000x speed so the computer could actually train faster.
But the side effect of this kind of training is that each level is a new experience. This is somewhat analogous to how infants learn to avoid holes while crawling, but then have to relearn that when they begin walking.
Yes but if it’s first instinct is “go left” on 1-2, it’s pretty apparent the reward function could use some tuning
If Code Bullet taught us anything training the AI is the hardest and most boring part.
Nintendo lawsuit in 4… 3… 2…


